RAG systems are easy to build and hard to trust. You can assemble a retriever, a vector store, and a chat model in an afternoon — but without a principled way to measure retrieval quality, faithfulness, and answer relevancy, every configuration change is a guess. This project is the measurement layer: a fully local RAG pipeline with a rigorous evaluation suite built on DeepEval, designed around iterative A/B comparison against a fixed benchmark.
The system runs entirely on local hardware (RTX 3090) via LM Studio, with GPT-4o-mini as the initial judge model for metric scoring. It targets a realistic mixed corpus — markdown documentation, shell scripts, and config files from a personal codebase — and tracks pipeline performance across four independent metrics as retrieval and generation strategies are swapped in and out.
System Architecture
The pipeline has two layers: a RAG pipeline that ingests documents, chunks them, stores embeddings in ChromaDB via a VectorStore abstraction, and generates answers at query time — and an evaluation layer that scores those answers across four DeepEval metrics.
flowchart LR D[Documents] --> C[Chunker] --> VS Q[Query] --> R[Retriever] R -->|embed + search| VS[(ChromaDB)] VS -->|ranked chunks| R R --> G[Generator] --> A[Answer] A --> F[Faithfulness] A --> AR[Answer Relevancy] R --> CP[Ctx Precision] R --> CR[Ctx Recall]
Every eval run writes a timestamped artifact folder (artifacts/eval_runs/<UTC>/) containing a structured report.json and a human-readable report.md with per-sample scores, metric reasoning, and pass/fail summaries. This makes regressions visible and improvements measurable — each pipeline variant leaves a permanent, comparable record.
The Dataset: Synthetic Q&A over a Real Codebase
The evaluation corpus is the documentation and configuration files for a personal Linux streaming setup (StreamDeck2) — markdown guides, install scripts, systemd units, and config templates. It is a small but realistic mixed technical corpus: prose, shell, service definitions, and system configuration in one place.
The 25-question synthetic dataset targets verifiable facts from that corpus: file paths, command-line flags, environment variables, service directives, and IPC details. The questions are grouped across five categories:
- Installation (
install, 10 questions) — exact behaviour ofinstall.sh: default user values, config file paths and modes, environment variables that control the install, AUR packages required - Systemd (
systemd, 4 questions) — service unit directives:User=,Requires=,After=,ExecStart=commands - Networking (
networking, 2 questions) — firewall port requirements, service ports, pairing protocols - MoonDeck / inter-process (
moondeck, 6 questions) — IPC primitives, singleton mechanics, Qt shared memory, env var contracts between processes - Xorg / display (
xorg, 3 questions) — Xorg flags, Modeline config, input isolation mechanics
Most questions are medium difficulty: specific enough to have one right answer, but often detailed enough to expose retrieval misses, chunking problems, or lightly hallucinated answers.
How the Evaluation Works
Each sample in the benchmark has a query, an expected answer, and no pre-specified context — the retriever must find the relevant chunks on its own. The pipeline generates an answer, then a judge model scores it across four independent metrics.
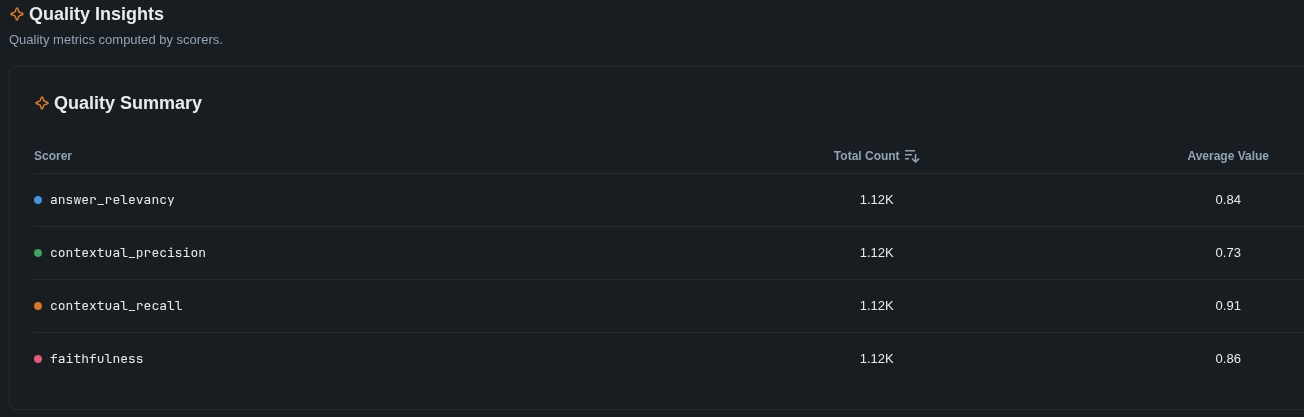
| Metric | What it measures | Threshold |
|---|---|---|
| Faithfulness | Are all claims in the answer supported by the retrieved chunks? Catches hallucination — the model adding facts beyond what was retrieved. | ≥ 0.70 |
| Answer Relevancy | Does the answer actually address the question asked? Catches tangential or evasive responses. | ≥ 0.70 |
| Contextual Precision | Are the most relevant chunks ranked highest in the retrieval results? A low score means relevant chunks exist but are buried under noise. | ≥ 0.60 |
| Contextual Recall | Do the retrieved chunks cover all the facts needed to answer the question? A low score means the retriever missed something important. | ≥ 0.60 |
These metrics are implemented via DeepEval (Confident AI). The conceptual definitions of Faithfulness and Answer Relevancy originate in the RAGAS paper — Es et al., 2023, published at EACL 2024 as a system demonstration — which introduced LLM-based, reference-free scoring for RAG pipelines. Contextual Precision and Contextual Recall were later additions to the RAGAS library, post-publication, and are adopted by DeepEval under the same conceptual definitions.
A sample passes only if all four metrics clear their thresholds. This means a perfectly faithful, well-written answer still fails if the retriever ranked its supporting chunks poorly — which keeps pressure on the whole pipeline, not just the generator.
The four metrics deliberately target different failure modes. Faithfulness and Answer Relevancy are generation-side: they catch a model that hallucinates or wanders off topic. Contextual Precision and Contextual Recall are retrieval-side: they catch a retriever that misses relevant chunks or buries them in noise. Separating these allows a pipeline change — say, switching from dense-only retrieval to hybrid BM25 + dense — to be attributed precisely to either retrieval or generation quality shifts.
A Sample in Detail
syn010 is representative of what the system does well — a debugging question about a non-obvious root cause:
Query
Why does MoonDeckStream fail with ‘Another instance already running!’ after a stream ends, and what is the root cause involving SIGTERM and quick_exit()?
Generated Answer (truncated)
The issue occurs because when Sunshine sends SIGTERM to MoonDeckStream, the signal handler calls std::quick_exit(128 + signum). Unlike a normal exit, quick_exit() does not run C++ destructors — so the QSharedMemory and QSystemSemaphore objects used as the singleton lock are never cleaned up. On Linux, System V IPC segments persist until explicitly released, so on the next launch the singleton check finds the orphaned segment and refuses to start.
Faithfulness
The score is 0.92 because the actual output incorrectly attributes management of QSharedMemory and QSystemSemaphore to the destructor of SingleInstanceGuard, while it is actually the responsibility of MoonDeckStream to ensure only one instance runs.
Answer Relevancy
The score is 1.00 because the response directly addresses the question about MoonDeckStream’s failure and the involvement of SIGTERM and quick_exit() without any irrelevant statements.
Contextual Precision
The score is 0.89 because the relevant nodes are well-ranked, with the first two providing direct answers. However, an irrelevant node in third position (a timeline without SIGTERM context) slightly lowers the score.
Contextual Recall
The score is 1.00 because every aspect of the expected output is thoroughly supported by the retrieval context — SIGTERM behaviour, quick_exit() semantics, and System V IPC persistence are all present.
The 0.917 faithfulness deduction is worth noting: the judge caught that the answer attributed cleanup responsibility to a destructor that doesn’t exist in the described architecture. A human reviewer reading quickly might have missed it. This is exactly the kind of subtle factual error — correct root cause, wrong attribution — that the evaluation is designed to surface.
RAG Improvements: Hybrid vs Dense Retrieval
The latest paired A/B study compares dense retrieval against hybrid retrieval (dense + BM25 fusion) over the same 25-question synthetic benchmark. The study used 10 completed runs per arm from the local MLflow store (study_id = 20260325T154618Z), pairing dense arm a with hybrid arm b by block index so each comparison shares the same dataset ordering.
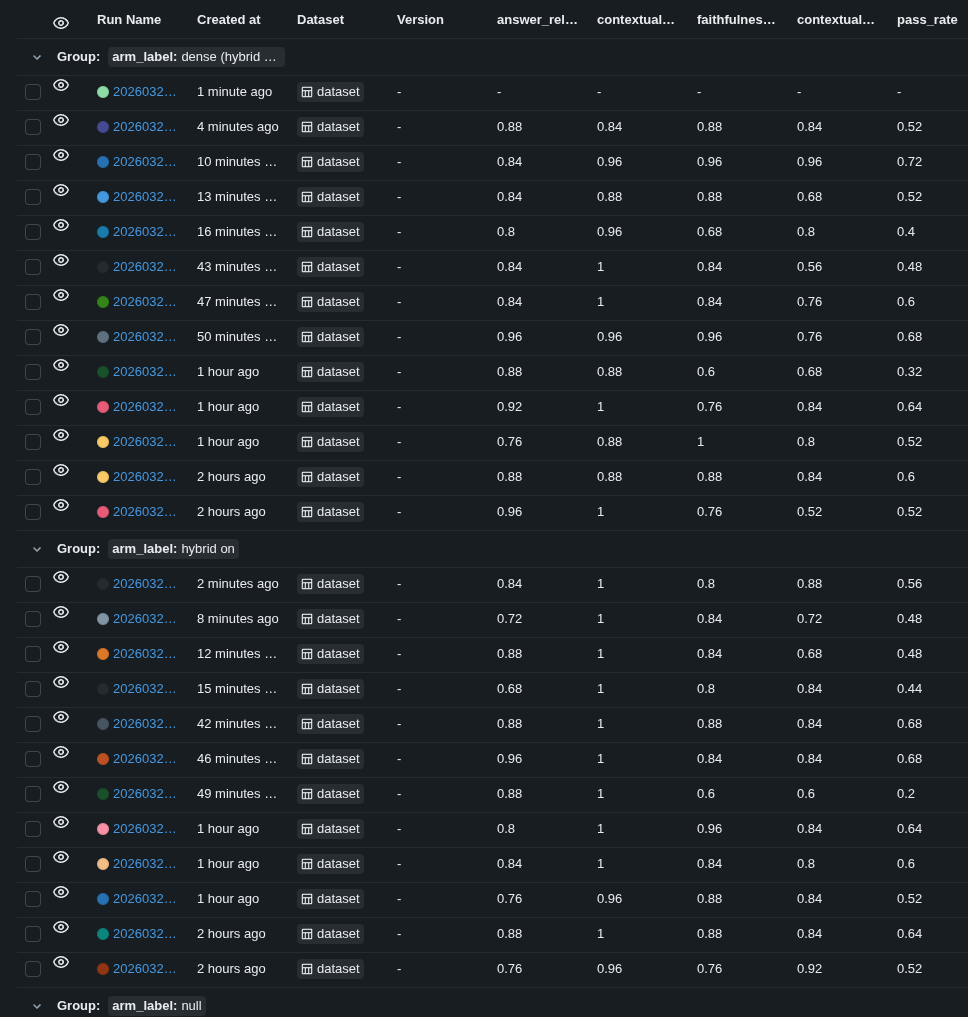
MLflow view of the paired hybrid-vs-dense study (rag-eval-system, study_id=20260325T154618Z).
| Metric | Dense mean | Hybrid mean | Delta |
|---|---|---|---|
| Pass rate | 0.52 | 0.48 | -0.04 |
| Faithfulness | 0.836 | 0.796 | -0.040 |
| Answer relevancy | 0.876 | 0.800 | -0.076 |
| Contextual precision | 0.720 | 0.772 | +0.052 |
| Contextual recall | 0.936 | 1.000 | +0.064 |
The cleanest result is retrieval completeness: hybrid hit perfect contextual recall on all 10 runs, while dense averaged 0.936. Hybrid also won contextual precision in 7 of 10 paired blocks, which is directionally consistent with BM25 + RRF recovering better supporting chunks for exact technical terms.
Pass rate did not improve, but the report shows that this is mostly a judge-quality problem rather than a retrieval regression. The strongest negative swing came from block 0, where hybrid fell from 0.68 to 0.20 pass rate. That drop was driven by faithfulness judgments on answers that were otherwise stable across runs; the same hybrid answer could be scored as fully supported in one block and unsupported in another.
What the study actually shows
- Hybrid improves retrieval coverage. Contextual recall was 1.0 on every hybrid run and hybrid won recall in 8 of 10 paired blocks.
- End-to-end pass rate is inconclusive. Hybrid won 5 blocks, dense won 4, and one block tied, but the mean delta stayed slightly negative at -0.04.
- The judge is the dominant source of variance. Across repeated scoring, faithfulness and contextual precision flipped on most sample-arm combinations, which means
pass_rateis heavily contaminated by judge noise.
Why the result is noisy
The report’s key finding is that GPT-4o-mini is not reliable enough for this judging task. Faithfulness and contextual precision behave close to coin flips on repeated evaluation of the same or near-identical answers, especially on technical questions involving file paths, service units, IPC, and system behavior. That noise is large enough to swamp the retrieval difference between the two arms.
This matters because pass_rate is an AND over all four metrics. Even if retrieval gets better, one unstable faithfulness or answer-relevancy call can flip the whole sample from pass to fail. In practice, the hybrid arm appears to retrieve slightly better context, but the current judge makes it hard to turn that into a trustworthy end-to-end verdict.
Takeaways
- Hybrid retrieval is a real improvement for retrieval completeness on this corpus.
- The study does not support the claim that hybrid is worse overall; the negative pass-rate delta is within judge noise.
- The next step is to upgrade the judge, not to keep rerunning the same study. A stronger model and raw score logging would make the existing A/B harness much more informative.